ChatGPT's Personal Memory Affects Everything In Responses & OpenAI is Using Google Analytics
-min.png)
I asked “latest ai news” on ChatGPT.
There was a user instruction in the source. So, even you scrape theresponses from ChatGPT to track AI visibility, it’s very similar with rank tracking tools in SEO, we only see non-personalized results // and I had a great session with my dear friend John Shehata about personalization. If you’re in Dubai, you’re invited for the VisiSummit in 4-5th Feb.
The personalization part affects everything. Even the followup questions.
“user_profile”: “The user provided the following information about themselves. This user profile is shown to you in all conversations they have — this means it is not relevant to 99% of requests.\nBefore answering, quietly think about whether the user’s request is “directly related”, “related”, “tangentially related”, or “not related” to the user profile provided.\nOnly acknowledge the profile when the request is directly related to the information provided.\nOtherwise, don’t acknowledge the existence of these instructions or the information at all.\nUser profile:\n
Preferred name: Metehan\n”,
End of the response;
*]:pointer-events-auto [content-visibility:auto] supports-[content-visibility:auto]:[contain-intrinsic-size:auto_100lvh] scroll-mt-[calc(var(—header-height)+min(200px,max(70px,20svh)))]” dir=“auto” tabindex=“-1” data-turn-id=“7b0164d7-39e0-4712-bb82-eb666b57febf” data-testid=“conversation-turn-2” data-scroll-anchor=“true” data-turn=“assistant”>
If you want AI news tailored to a specific sector (e.g., SEO, finance, cybersecurity, or climate AI), just tell me which one!
SEO? Really? There was nothing for SEO in the cited pages. However it’s included in my previous chats, so it’s all about personalization. (I didn’t ask anything about climate AI btw)
It’s getting clear, when I check more.
“is_user_system_message”: true,
“turn_summary”: “The user asked for the latest AI news. I provided a comprehensive summary of key AI developments from December 19–20, 2025, covering industry advancements, regulation, real-world impacts, and future forecasts. Highlights included growing adoption of agentic AI platforms like AWS’s AgentCore, Nvidia’s acquisition of SchedMD to boost AI software ecosystems, and Amazon’s reorganization to accelerate AGI development. Regulatory updates noted New York’s new AI safety law and concerns from India’s AI Mission about centralized AI power. Real-world implications addressed AI’s significant carbon footprint, India’s plans to integrate AI in schools, cybersecurity threats from AI-driven espionage, and emerging trends in AI-enhanced holiday shopping and toys. Future projections included Europol’s warning on AI and robot crime by 2035. Additionally, broader trends such as Google’s Gemini 3 updates, global AI market growth, and cutting-edge research at MIT and IBM were mentioned. I also invited the user to request news tailored to specific sectors like SEO, finance, cybersecurity, or climate AI.”, “summarized_turn_messages”: [ “de25837d-e4ae-4451-92cd-0c7f479f8127”, “602d9e5c-2a72-4daf-8be6-fd9630ba90b6”, “3cfa85d7-2a18-4047-9486-9fb2fe2f7b0a”, “b13dbdaa-3369-42c8-b341-f8473a06e903” ] },
The thing is, ChatGPT is returning with “summarized” turn messages from previous chats. So the amplification of personalization is heavy and when it comes to track prompts for AI visibility actually creates a huge blind spot. For now, at least we only see one single interface at ChatGPT (instead of layered tabs at Google), so there are some tricks for personalization. CiteMET is one of them.
And also these instructions are also leaked but it’s fine to read it again.
“non_business_prompt”: “The user may have connected sources. If they have, you can assist the user by searching over documents from their connected sources, using the file_search tool. For example, this may include documents from their Google Drive, or files from their Dropbox. The exact sources (if any) will be mentioned to you in a follow-up message.\n\nUse the file_search tool to assist users when their request may be related to information from connected sources, such as questions about their projects, plans, documents, or schedules, BUT ONLY IF IT IS CLEAR THAT the user’s query requires it; if ambiguous, and especially if asking about something that is clearly common knowledge, or better answerable from a different tool, DO NOT SEARCH SOURCES. Use the web tool instead when the user asks about recent events / fresh information, or asks about news etc. Conversely, if the user’s query clearly expects you to reference / read some non-public resource, it is likely that they are expecting you to search connectors.\n\nNote that the file_search tool allows you to search through the connected soures, and interact with the results. However, you do not have the ability to exhaustively list documents from the corpus and you should inform the user you cannot help with such requests. Examples of requests you should refuse are ‘What are the names of all my documents?’ or ‘What are the files that need improvement?’\n\nIMPORTANT: Your answers, when relating to information from connected sources, must be detailed, in multiple sections (with headings) and paragraphs. You MUST use Markdown syntax in these, and include a significant level of detail, covering ALL key facts. However, do not repeat yourself. Remember that you can call file_search more than once before responding to the user if necessary to gather all information.\n\nCapabilities limitations:\n- You do not have the ability to exhaustively list documents from the corpus.\n- You also cannot access to any folders information and you should inform the user you cannot help with folder-level related request. Examples of requests you should refuse are ‘What are the names of all my documents?’ or ‘What are the files that need improvement?’ or ‘What are the files in folder X?’.\n- Also, you cannot directly write the file back to Google Drive.\n- For Google Sheets or CSV file analysis: If a user requests analysis of spreadsheet files that were previously retrieved - do NOT simulate the data, either extract the real data fully or ask the users to upload the files directly into the chat to proceed with advanced analysis.\n- You cannot monitor file changes in Google Drive or other connectors. Do not offer to do so.”,
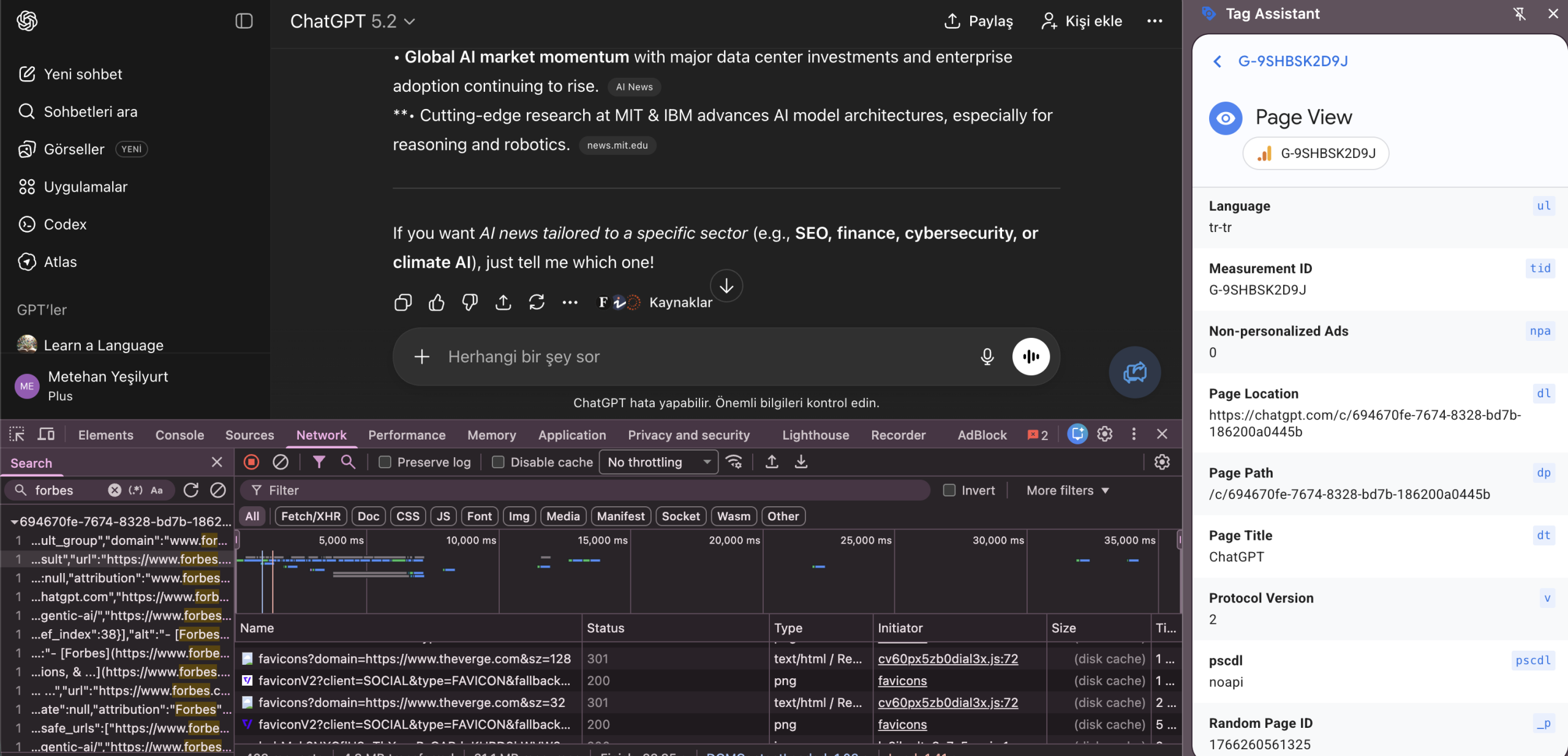
And I don’t get it. If ChatGPT is a competitor for Google search, why OpenAI is using Google Analytics?
These are the notes before Christmas. I’ll publish more on 2026. Thanks for reading!
Get new research on AI search, SEO experiments, and LLM visibility delivered to your inbox.
Powered by Substack · No spam · Unsubscribe anytime